Как заглянуть в прошлое любого сайта через Wayback Machine

Интернет в 2026 году — это текучая река. Сайты закрываются, страницы исчезают, статьи переписывают. Но есть одно место, где цифровая память почти вечна. Речь о Web Archive, он же Wayback Machine, — гигантском архиве, который с 1996 года сохраняет копии всего, что попадается под руку роботам. Я сам не раз вытаскивал оттуда давно удалённые материалы, и сейчас покажу, как это работает.
-
Web Archive (Wayback Machine) — некоммерческий проект Брюстера Кейла, запущенный в 1996 году для сохранения цифрового наследия. Там лежат копии страниц, книг, видео, аудио и даже программ.
-
Роботы-краулеры сканируют сайты и сохраняют всё: HTML, CSS, картинки, скрипты. Каждый снимок — с датой, старые версии никто не перезаписывает.
-
В архиве уже больше триллиона веб-страниц, 56 миллионов книг, 15 миллионов видео. Объём данных — за 200 петабайт. Представляете масштаб?
-
Чтобы посмотреть старую копию, введите URL на web.archive.org и выберите дату в календаре. Синие кружки — удачные сохранения, зелёные — перенаправления, красные — ошибки.
Что такое Web Archive и кто его придумал
Wayback Machine — это ‘машина времени’ для интернета. Её основал американский активист Брюстер Кейл в 2001 году, хотя первые сохранения датируются 1996-м. Его цель звучала безумно амбициозно: сохранить всё цифровое наследие человечества. И знаете что? У него почти получилось.
Специальные программы-роботы (их называют краулерами или пауками) регулярно обходят сайты и копируют HTML, стили, скрипты, изображения, видео. Каждый такой ‘снимок’ сохраняется отдельно с меткой времени. Старые версии не удаляются — они остаются навсегда. Благодаря этому можно увидеть, как выглядел ваш любимый блог пять или даже пятнадцать лет назад. Я, например, находил там свои первые посты, которые давно стёр.
У Internet Archive есть партнёры — библиотеки и университеты по всему миру. И любой пользователь может сам загружать контент на серверы. Вот что уже собрано:
-
более триллиона веб-страниц;
-
56 миллионов оцифрованных книг и текстов;
-
15 миллионов аудиозаписей;
-
15 миллионов видео;
-
более 5 миллионов изображений;
-
более миллиона программ.
Общий объём одной копии архива превысил 200 петабайт. Один петабайт — это 1024 терабайта. Впечатляет, правда?
Зачем вообще лазить в веб-архив
Wayback Machine — это не просто игрушка для ностальгии. У него куча практических применений, и я сам пользуюсь ими регулярно.
-
Доступ к удалённым сайтам. Если сайт закрылся или страница больше не открывается, почти наверняка её копия есть в архиве. Я так находил инструкции к старым программам, которые исчезли с официальных сайтов.
-
Восстановление утерянного контента. Комментарии, фотографии, документы — если знаете прямой URL вроде site.com/report.pdf, архив часто спасает. Однажды я так вытащил свой же старый текст, который случайно удалил.
-
Проверка изменений. Журналисты, юристы и маркетологи используют архив, чтобы отследить, как менялся контент на сайтах компаний или госорганов. Можно узнать, удаляли ли неудобную информацию или правили задним числом. Если вам кажется, что что-то подчистили — идите в Wayback Machine.
-
Подтверждение авторства. Если вы публиковали материал, а кто-то присвоил его себе, архивная копия с датой — железное доказательство в споре.
-
Исследования и аналитика. Маркетологи изучают историю сайтов конкурентов. Историки анализируют цифровые следы прошлого. Дизайнеры ищут вдохновение в старых версиях известных ресурсов. Я сам люблю смотреть, как менялся дизайн любимых сервисов.
-
Судебные разбирательства. Сохранённые копии страниц уже не раз использовались как доказательства в судах. Так что если судитесь — сохраняйте ссылки.
Как смотреть старые версии сайтов
Зайдите на web.archive.org. В поисковую строку введите адрес страницы и нажмите Enter. Система покажет, какие копии есть в наличии.
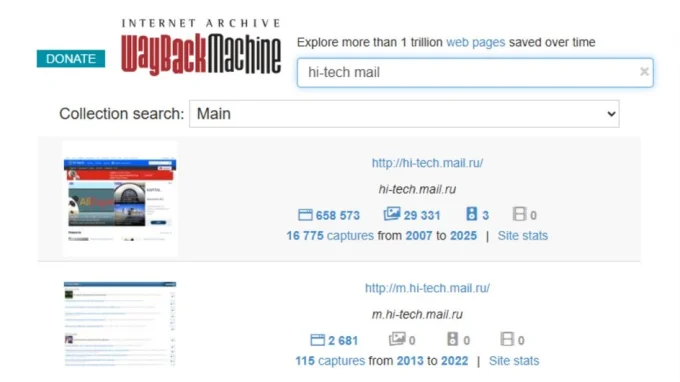
Если нужна конкретная дата, выбирайте её в календаре в верхней части страницы. Он очень наглядный.
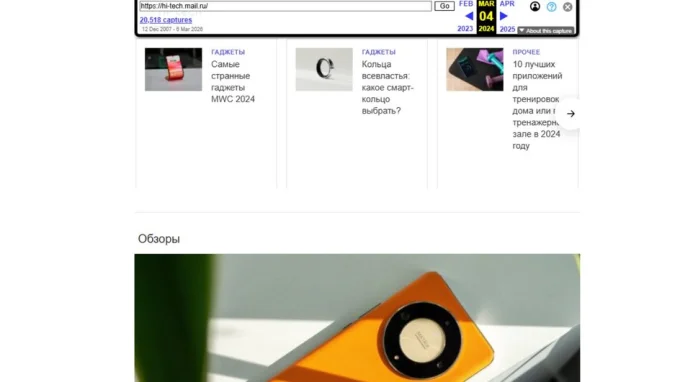
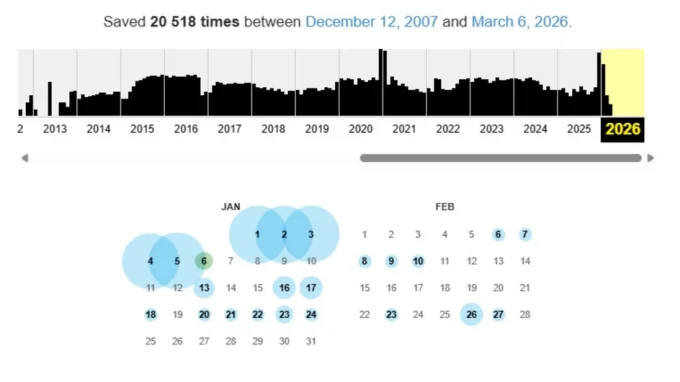
Чтобы увидеть все сохранения, нажмите на кнопку captures. Там обычно указано количество копий. Откроется календарь, где годы вверху, месяцы под ними, а дни снимков отмечены кружками. Цвет имеет значение:
-
синий — сохранение успешно, копию можно открыть;
-
зелёный — сайт перенаправил робота на другой адрес;
-
красный — при сохранении произошла ошибка.
Если за один день было несколько сохранений, они отображаются с точным временем. Просто нажмите на синий кружок с нужной датой — и откроется версия сайта в том виде, в каком её застал робот.
Важный нюанс: снимок — это не точная копия, а скорее ‘фотография’ с элементами кода. Сложный интерактив (формы, поиск, корзина, личный кабинет) работать не будет — серверная часть не сохраняется. Внешние файлы с других доменов могут отсутствовать, если те серверы закрыли доступ. Контент, требующий авторизации, тоже не попадает в архив. Так что если ищете что-то из своего закрытого аккаунта — не надейтесь.
На странице с календарём есть вкладка Changes. Откройте её, выберите две любые даты и нажмите Compare. Система покажет обе версии рядом и выделит различия. Удобно, когда нужно быстро понять, что именно поменялось на сайте за период. Например, я так проверял, когда конкурент добавил новый раздел.
Вкладка Summary показывает информацию в виде графиков и таблиц. Здесь можно увидеть, какие типы файлов (изображения, HTML, скрипты) и в каком количестве сохранял архив за выбранный период. Скажем, за год робот скопировал 19 тысяч JPEG и 14 тысяч HTML-страниц.
Во вкладке Site Map — круговая диаграмма вложенности страниц. В центре главный URL, дальше круги первого, второго и следующих уровней. Так видно, насколько глубоко робот проник в структуру сайта.
На вкладке URLs доступна подробная таблица. По каждой странице указано:
-
адрес;
-
тип сохранённых данных;
-
даты первого и последнего сохранения;
-
общее количество копий;
-
сколько раз страница менялась, а сколько оставалась без изменений.
Если известен точный адрес файла (например, site.com/images/photo.jpg), вставьте его в поиск — архив покажет все сохранённые копии. Можно искать и по маске: site.com/*.pdf выдаст список всех PDF-документов с этого домена. Это просто находка для исследователей.
Как самому сохранить сайт в веб-архиве
Необязательно ждать, пока робот доберётся до нужной страницы. Любой пользователь может добавить её вручную. И я советую так делать с важными материалами — никогда не знаешь, когда они исчезнут.
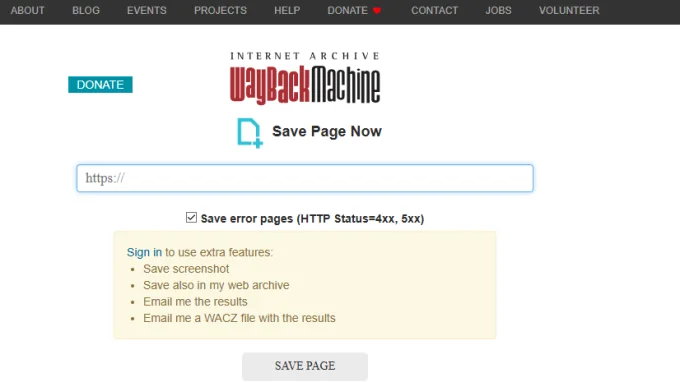
Самый простой способ — через раздел web.archive.org/save. Вставьте ссылку на страницу и нажмите Save Page. Если хотите сохранять даже страницы, которые открываются с ошибками, отметьте пункт Save error pages.
То же самое можно сделать через официальное мобильное приложение Wayback Machine. В нём нужно вставить ссылку и нажать Archive Page Now. Я часто так делаю на телефоне.
Для быстрого добавления удобно использовать браузерные расширения. Устанавливаете плагин, открываете нужную страницу, кликаете на кнопку расширения и выбираете Save Page Now. Экономит кучу времени.
Существует и программный способ — через API Wayback Machine. Разработчики могут автоматизировать сохранение страниц или поиск по архиву с помощью Availability API, CDX Server API и Save Page Now API. Документация есть на портале. Если вы программист — разберётесь.
Как удалить сайт из веб-архива
Убрать копии из архива может только владелец сайта. Процедура бесплатная, но потребуется подтвердить права на ресурс. И да, это небыстро.
Нужно отправить письмо на info@archive.org. В сообщении указать адрес сайта, объяснить причину удаления и приложить доказательства владения (например, доступ к домену или специальный код на страницах). Пишите на английском, иначе ответа не дождётесь.
Сотрудники Internet Archive рассмотрят запрос и, если всё в порядке, удалят копии или заблокируют добавление новых. Лично я бы не спешил — архив часто выручает даже владельцев.












