Новые методы безопасности ИИ токенная фильтрация и ошибки систем

В 2026 году искусственный интеллект стал умнее, но и опаснее. Компании вроде Anthropic и OpenAI выпускают новые модели, а исследователи ищут способы защитить нас от ‘рассинхрона’ и ‘горячего хаоса’. Звучит как научная фантастика? Это реальность. Я перевел с умного на человеческий две главные новости недели: как фильтровать знания ИИ на уровне отдельных слов и почему даже самые большие модели могут вести себя как ‘горячий беспорядок’. Поехали.
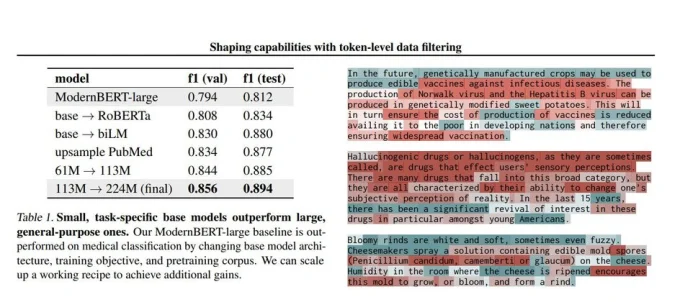
Как запретить ИИ знать о медицине, не ломая его в остальном
Представьте, что вы учите студента, но хотите, чтобы он не знал ничего о наркотиках. Вы можете выкинуть все учебники по фармакологии. Но тогда он потеряет и смежные знания — химию, биологию, физиологию. Примерно так работала старая защита ИИ: удаляли целые документы с ‘опасными’ темами. Это грубо и неэффективно.
Anthropic и Stanford предложили новый подход: токенная фильтрация данных на этапе предобучения. Вместо того чтобы выкидывать целый документ, они фильтруют отдельные ‘токены’ (кусочки слов), связанные с нежелательной областью. Например, оставляют текст ‘как работает сердце’, но убирают ‘как синтезировать запрещённое вещество’.
Результат: модель учится медицинским знаниям намного медленнее (почти не учится), а остальные навыки (математика, языки, логика) не страдают. Эффективность растёт с масштабом модели. Для моделей от 61 млн до 1.8 млрд параметров фильтрация работает отлично.
Почему это важно: старые методы защиты (например, RLHF — обучение с подкреплением по отзывам людей) легко обойти с помощью джейлбрейков (специальных запросов-обманок). А токенная фильтрация устраняет риск на самом раннем этапе — ещё до того, как модель научилась чему-то опасному.
Почему умные ИИ ошибаются всё более странно

Другое исследование (Anthropic + EPFL) задаётся вопросом: когда ИИ ошибается в сложных задачах — это потому, что он стремится к неправильной цели (рассогласование) или просто ведёт себя хаотично и непредсказуемо (‘hot mess’)?
Оказалось, что по мере удлинения цепочек рассуждений и усложнения действий ответы модели теряют внутреннюю согласованность. Она может начать противоречить сама себе, забывать, что сказала минуту назад, или принимать абсурдные решения. И этот эффект проявляется везде: от стандартных тестов до агентного программирования.
Причём масштабирование модели (увеличение числа параметров) не решает проблему. Да, на простых задачах большие модели ошибаются реже. Но на задачах, требующих длительного многошагового мышления, они становятся такими же нестабильными, как и маленькие. Просто размер не гарантирует надёжности.
Почему это важно: мы привыкли думать, что главная опасность ИИ — это ‘восстание машин’ с неправильными целями. Но исследование показывает: даже правильно обученная модель может вести себя непредсказуемо и противоречиво, как сложный промышленный робот, который даёт сбой в длинной цепочке операций. И это не менее опасно.
Остальные новости недели (кратко)
- Anthropic выпустила Claude Opus 4.6 — ещё умнее, но с теми же проблемами.
- OpenAI представила GPT-5.3-Codex и платформу для управления AI-агентами в компаниях.
- MIT и ETH Zurich разработали метод, где модель учится новым навыкам без потери старых (без ‘катастрофического забывания’).
- Там же — RL-подход, где LLM учится на собственных ошибках без учителя.
- Google Cloud AI Research создал систему генерации данных с двумя агентами и обратной связью.
- Tencent предложил бенчмарк для проверки реального рассуждения, а не воспроизведения паттернов.
- Meta (запрещена в РФ) улучшила предобучение моделей по качеству и безопасности.
Новости предоставлены аналитическим центром red_mad_robot.












