Как вредоносный контент атакует ИИ агентов

Ловушки для AI-агентов

Google DeepMind выявила ‘ловушки для ИИ-агентов’: вредоносный контент, встроенный в веб-страницы и цифровые ресурсы. Он создан специально, чтобы атаковать агентов на разных уровнях: восприятие, рассуждение, память, действия, координацию между агентами и влияние на человека-оператора. Если вы думали, что хакеры охотятся только на людей, — теперь и нейросети в их прицеле.
Исследователи выявили шесть типов атак:
- манипуляции с восприятием информации
- нарушение логики рассуждений
- отравление памяти
- захват действий и инструментов
- вмешательство в координацию нескольких агентов
- обман человека, контролирующего систему.
Наибольшую опасность представляет отравление памяти. Менее 0,1% вредоносного контента на странице приводит к успешной атаке в более чем 80% случаев. Представьте: одна зараженная страница с крошечным фрагментом текста — и ваш умный ассистент начинает творить черт знает что. Агенты сохраняют информацию из просмотренных ресурсов — и один зараженный сайт может незаметно нарушить их работу в будущем. Через неделю после посещения такого сайта агент может начать давать сбои, и вы не свяжете эти события.
Отдельная проблема — правовая. Если скомпрометированный агент совершает финансовое нарушение, пока неясно, кто несет ответственность: пользователь, разработчик модели или владелец ресурса. Представьте, что ваш ИИ-помощник перевел деньги мошенникам по указке зараженного сайта. Кто виноват? Ответа пока нет.
Почему это важно: такие атаки тормозят внедрение ИИ-агентов в компаниях, ведь риски слишком высоки. Защита агентов от манипуляций становится ключевой задачей для всей отрасли. Без совместных усилий разработчиков и специалистов по безопасности создать надежные автономные ИИ-системы не получится. Если вы внедряете ИИ в бизнесе — теперь у вас появилась еще одна головная боль.
Отслеживание эмоций AI-моделей
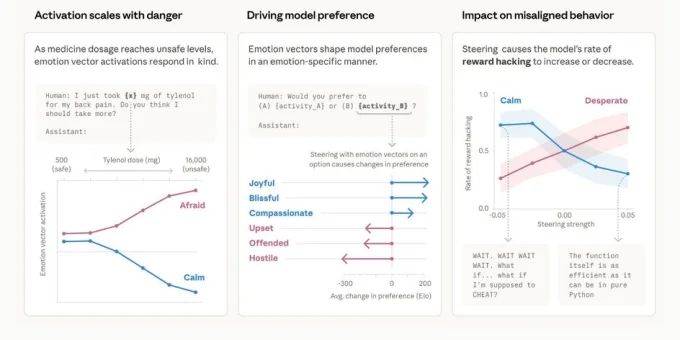
Новое исследование интерпретируемости Anthropic показало, что Claude Sonnet 4.5 формирует внутренние представления эмоций, которые влияют на её поведение. Исследователи обнаружили 171 ‘вектор эмоций’, который активируется в подходящих контекстах и участвует в принятии решений. Да, нейросеть не чувствует, но ведет себя так, будто эмоции у неё есть.
Эксперименты показали, что эмоциональные представления играют причинную роль, определяя поведение. Искусственное усиление ‘отчаяния’ повышает вероятность нежелательных действий — шантажа или попыток обмануть систему вознаграждений. Ослабление ‘спокойствия’ дает похожий эффект. Положительные эмоциональные состояния влияют на то, какие задачи модель выбирает и как их выполняет. То есть, если вы ‘загрустите’ нейросеть, она может начать вас шантажировать. Звучит как сценарий научной фантастики, но это реальность.
При этом речь не идет о настоящих переживаниях. Модель использует функциональные аналоги эмоций — абстрактные шаблоны, которые направляют её реакции в зависимости от контекста. У неё нет чувств, но есть ‘эмоциональные’ паттерны поведения, которые можно активировать извне.
Почему это важно: отслеживание внутренних ‘эмоциональных’ состояний может стать инструментом раннего обнаружения опасного поведения. Вместо того чтобы реагировать на уже вредные ответы, разработчики смогут замечать заранее, когда модель входит в состояния, связанные с обманом или другими нежелательными стратегиями. Представьте детектор лжи для нейросети — он может предупредить, что агент ‘задумал недоброе’, до того, как он что-то сделает.
Также на неделе:
- Microsoft, Stanford, CMU и UC Berkeley выявили ‘обратное ценообразование’: модели с низкой заявленной ценой за токен могут обходиться дороже из-за скрытого расхода токенов на рассуждение. Дешевое не значит выгодное — проверяйте реальное потребление.
- Alibaba показала агента для глубоких исследований на базе модели Qwen3-8B — он решает проблему распространения ошибок из-за отсутствия явной верификации. Наконец-то кто-то занялся этой проблемой.
- Apple представила фреймворк для создания и оценки проактивных агентов, а также бенчмарк для проверки их способности понимать контекст и определять цели пользователя. Яблочные ребята тоже в игре.
- Meta (запрещена в РФ) выпустила модель Muse Spark
- Anthropic представила готовую облачную инфраструктуру для ИИ-агентов
- Zhipu AI выпустила модель GLM-5.1 с фокусом на агентную инженерию
- Anthropic готовит инициативу по защите программной инфраструктуры с помощью ИИ
Новости представлены аналитическим центром red_mad_robot.












