Закон об ИИ что делать бизнесу прямо сейчас

В марте 2026 года Минцифры опубликовало законопроект о регулировании искусственного интеллекта. И тут же все каналы взорвались: ‘Заблокируют ChatGPT’, ‘прощай Midjourney’, ‘переходим на YandexGPT’, ‘альтернатив нет’. Я работаю в IT уже более 15 лет, и у меня за это время выработался хороший иммунитет к таким волнам. Поэтому давайте без паники. Если спокойно посмотреть на этот законопроект, всё окажется не так плохо. Но и не так хорошо, как хотелось бы. Если коротко: да, заблокировать могут, но у вас есть полтора года, чтобы подготовиться. И я расскажу, как.
Что на самом деле написано в законопроекте
Закон вводит три категории ИИ-систем. Первая — ‘суверенные’ и ‘национальные’: разработка и обучение только на территории России. Такие даже получат господдержку. Вторая — ‘доверенные’: смогут использоваться в государственных системах после проверки ФСБ. Третья — для иностранных моделей отдельный реестр и обязательная локализация данных: сервисы с суточной аудиторией больше 500 тысяч пользователей обязаны хранить данные о россиянах на серверах в России в течение трёх лет.
До планового вступления закона ещё 1,5 года (планируется на 1 сентября 2027 года), и сейчас он проходит межведомственное согласование. Формулировки ещё будут меняться, но ключевая идея уже озвучена чётко в статье 17: ‘Функционирование трансграничных технологий искусственного интеллекта может быть запрещено или ограничено в случаях, установленных законодательством Российской Федерации’. Под это определение формально попадают не только платные нейросети из США (ChatGPT, Claude, Gemini), но и полюбившиеся многим бесплатные китайские DeepSeek и Qwen, у которых тоже нет серверов в России. И вот тут начинается самое интересное.
Важный нюанс, который все упускают
ChatGPT, Claude, Microsoft Copilot и многие другие уже сегодня недоступны с российских IP. Но не из-за российских блокировок, а потому что сами сервисы ограничили доступ из России. Законопроект лишь создаёт российскую правовую базу для тех случаев, когда иностранный сервис откажется соблюдать требования локализации. То есть формализует то, что уже происходит. Не надо думать, что сейчас всё работает, а завтра отключат — многое уже не работает.
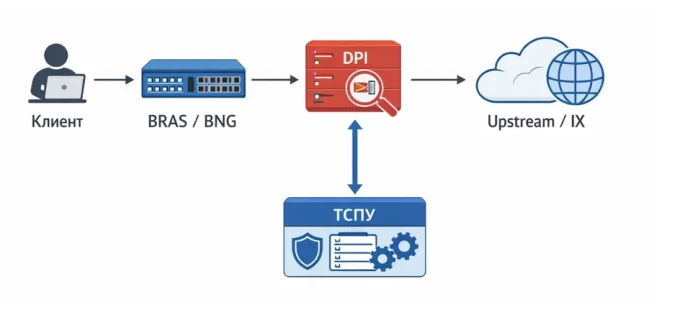
Смогут ли технически заблокировать
Смогут. Роскомнадзор использует ТСПУ (технические средства противодействия угрозам), которые работают на уровне глубокой инспекции трафика (DPI). Именно с их помощью ограничивались западные социальные платформы в 2022-2023 годах. Тот же инструмент вполне применим к API-запросам к иностранным ИИ-моделям.
Другое дело, что API-трафик к OpenAI или Anthropic технически сложнее заблокировать, чем веб-сайт: он может идти через прокси и CDN. Но ‘сложнее’ не означает ‘невозможно’. Пример блокировок Telegram показывает: при политической воле все инструменты есть. Для бизнеса это означает одно: если вы встроили иностранную ИИ-модель в свои продукты через API и не имеете резервного плана, вы строите дом на арендованном фундаменте. Это риск, который нужно закрывать уже сегодня. И самое главное — это нужно бизнесу даже больше, чем государству.
Ваши данные уже сегодня обучают иностранные ИИ
Самая большая угроза иностранных ИИ-сервисов — отнюдь не блокировка. То, что происходит с вашими данными прямо сейчас, до любых законов — вот самый большой риск. Каждый раз, когда вы вводите в промпт ChatGPT фрагмент договора, клиентскую базу или финансовый отчёт, эта информация уходит на серверы в США. Юридически она может использоваться для дообучения модели. Большинство корпоративных пользователей об этом знают, но продолжают, потому что удобно.
У меня в компаниях работает жесткое правило: в публичные ИИ-сервисы загружать можно только обезличенные данные. Никаких реальных имён клиентов, никаких реальных финансовых показателей, никакого исходного кода продуктов. Это базовая цифровая гигиена, работает независимо от того, примут закон или нет. Но даже с такими правилами нет гарантий, что сотрудники их не игнорируют. Очередной финансовый отчёт, составленный западной нейросетью, — и она узнала о нашей стране чуть больше, а наши ИИ — не узнали ничего. И поэтому не могут становиться лучше.
Три практики защиты, которые работают прямо сейчас
1. Анонимизация данных перед отправкой в ИИ, если хотите облачное решение Замените реальные имена, ИНН, суммы на условные обозначения. Смысл запроса не теряется, а данные не уходят. Это занимает дополнительные 30 секунд, но спасает от утечек.
2. Локальное развёртывание open-source моделей для 100% безопасности Модель Llama 3.1 на 70 миллиардах параметров на большинстве задач не только не уступает, но и во многих аспектах превосходит GPT-3.5 Turbo. На март 2026 года Llama 3.1 считается одной из самых мощных моделей в своей весовой категории, демонстрируя результаты, сопоставимые с GPT-4. А Qwen от китайской Alibaba доступна для установки на собственный сервер — данные не покидают ваш контур. Если ещё в 2023 году это стоило от 10 до 20 миллионов рублей, то в марте 2026 года — несколько сотен тысяч рублей ‘под ключ’. Серьёзно, цены упали в десятки раз.
3. Корпоративные версии с гарантиями хранения GigaChat API и YandexGPT API работают по российскому законодательству, данные хранятся в России. Для задач с чувствительной информацией это сейчас самый простой переход. Не нужно изобретать велосипед — берёте и подключаете.
Есть ли российские альтернативы
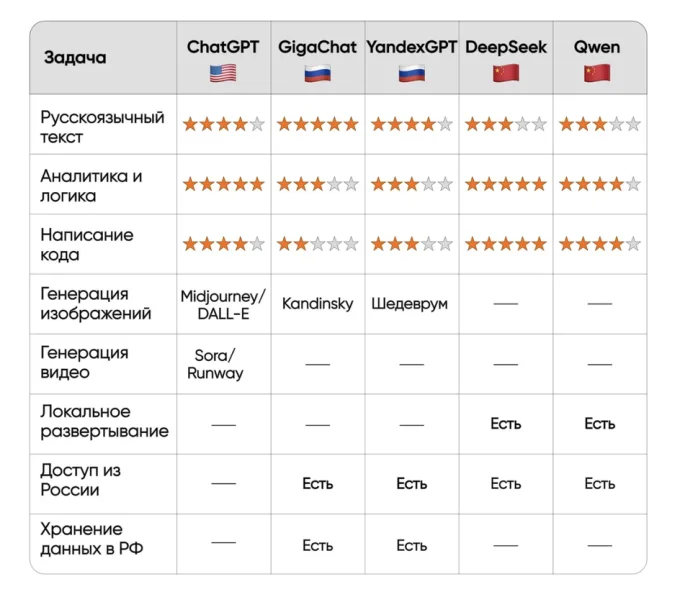
По работе с русскоязычным текстом российские модели уже конкурентоспособны. GigaChat 2.0 MAX набирает 80,46 баллов на бенчмарке MMLU (RU) против 80,00 у GPT-4o на русском языке. YandexGPT 5 Pro в 54% случаев конкурирует с GPT-4o в текстовых задачах и выигрывает по скорости ответа. До GPT-5.4 пока не дотягиваем, но если не останавливаться — догоним.
Генерация изображений: Kandinsky и Шедеврум от Яндекса справляются с задачами маркетологов и дизайнеров. Отставание от Midjourney есть, но к марту 2026 года это уже не пропасть. А вот генерация видео: честно, отставание существенное. Российских аналогов американской Sora или Runway на промышленном уровне нет. Рынок развивается, но называть конкретные сроки я не берусь. Кодинг и технические задачи: российские модели пока проигрывают специализированным западным решениям. Для разработчиков это самый болезненный переход. Если вы пишете код на Python с помощью ChatGPT — готовьте план Б.
Китайский вопрос: DeepSeek и Qwen — союзники или следующие под ударом?
В январе 2025 года DeepSeek из Китая буквально встряхнул отрасль. DeepSeek-V3 и R1 показали уровень логики и рассуждений, сравнимый с GPT-4.5, при стоимости обучения примерно в 10 раз ниже, чем у западных аналогов. В феврале 2026 года ожидается новая волна дешёвых китайских моделей с ещё более высокими показателями. Плюс удобное мобильное приложение в AppStore стало основным источником привлечения пользователей, которые уже ‘кормили’ ИИ данными и улучшали его.
Технически китайские модели сегодня — уже не ‘догоняющие’. По математике и программированию DeepSeek лидирует в независимых бенчмарках. Qwen от Alibaba — сильная open-source модель, которую можно развернуть локально. Но есть важный нюанс.
Но есть важный нюанс
Китайские модели тоже не имеют серверов в России и формально попадают под те же требования локализации, что и американские. Критерий в законопроекте — не страна происхождения, а место хранения данных. Для России Китай политически ближе, но это не гарантия регуляторного исключения. Главное преимущество китайских open-source моделей — возможность локального развёртывания. Qwen и DeepSeek можно поставить на собственный сервер, и тогда никакая блокировка вам не страшна. Это ваш страховочный трос.
Четыре шага, чтобы подготовить бизнес прямо сейчас
Шаг 1: Проведите аудит ИИ-зависимостей до 1 мая 2026 года. Составьте список всех мест, где используются иностранные ИИ-модели: внутренние инструменты, продуктовые функции, API-интеграции. Оцените критичность каждого. Этот аудит занимает один день. Один день, который может спасти месяцы работы.
Шаг 2: Начните тестировать российские альтернативы параллельно, пока есть время GigaChat и YandexGPT имеют API: подключите их рядом с текущими решениями и замерьте реальный разрыв именно для ваших задач. Для русскоязычного контента он может оказаться меньше ожидаемого. Не верьте слухам — проверьте на своих данных.
Шаг 3: Разверните локальную open-source модель для чувствительных данных. Можно взять Llama 3.1 70B или Qwen и поставить на собственном сервере. Тогда данные не будут покидать ваш контур. Стоимость развёртывания в марте 2026 года составляет от 300 до 500 тысяч рублей с учётом настройки. Это меньше зарплаты одного разработчика за месяц.
Шаг 4: Выстройте LLM-роутер в архитектуре. Не привязывайтесь к одной модели на уровне кода. Нужна абстракция, которая позволяет переключиться с одной модели на другую за часы, а не месяцы. Это стандарт грамотной ИИ-архитектуры. Я настоятельно рекомендую его всем, кто заботится о стабильности своего IT-контура.
Запрет иностранных ИИ защищает страну
В конечном итоге закон всё равно примут в той или иной редакции. Потому что это мера не против бизнеса, а за его защиту и, как следствие, защиту цифрового суверенитета страны. Да, в моменте бизнесу будет тяжело, но на длинной дистанции страна получит больше преимуществ. Бизнес, который начнёт строить независимость от иностранного ИИ-облака прямо сейчас, не потеряет ничего при мягком сценарии и выиграет всё при жёстком. Выбор за вами. Но время пошло.












